
MIT-6.5840-KVRaft
额,看了下上次更新文章居然已经是一个月之前了。
Emm。。。首先这个月确实有点摆,感觉在Raft上有些吹毛求疵,花了将近一个月的时间去处理一些潜在的bug(然而lab4还是暴露出了一大堆)。还有就是随着学期进入期中,多了一些难受的实验课(一学分实验让我抄了50页报告),空闲时间没有之前多了。进入冬季日常犯困的情况也多了起来。总之这个月确实进度非常缓慢,只完成了lab4。按这个进度下去12月中旬应该就可以完成全部lab了,到时候考虑下是进一步学习还是尝试下导师给的课题吧。
总的来说lab4并不困难,只要你的raft的实现的足够好的话,但非常可惜我的raft存在很多问题,大部分时间都花在和raft.go搏斗上了。
通过测试的时间正好和要求的400s一致,就是不知道为什么4A的测试负载比想象中高了太多,一次测试没办法起太多进程,在自己的电脑上同时运行30个就是极限,在2核的云服务器上同时运行5个就是极限了。与之对比,4B的测试在本地PC上却能同时运行100个。所以这次的测试就没有搞10000次,只做了两三千次,感觉肯定还有bug没有显现出来
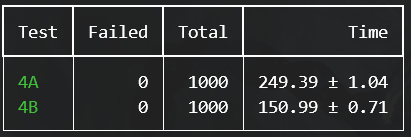
10000次的测试结果如下(比之前稍慢是因为同时运行个数设置的有点激进,所以稍微慢了一点)
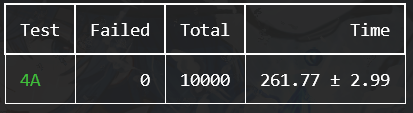

对原先Raft的不足之处的修改
这部分反省下原先的Raft的实现的不足以及解决方案
在Leader当选时立刻添加一条空日志
首先明确一点,Leader应该只commit当前任期内的日志,如果不保证这点就会出现论文中Figure 8的不一致状态。
然后考虑这样一个情况:
S1: 1 1 1 2 2
S2: 1 1 1 2
S3: 1 1 1 2 2
上面的数字代表日志的任期号,假设S1为Leader,任期为2,它添加了两条日志,并且都达成了commit条件。然后此时S1崩溃,重新恢复后,假设从S3中选举出,任期为3。
这时根据我们的基本设定,Leader只commit它任期内的日志,S3没有权力commit任期2的第二条日志。这时如果上层应用不调用Start()来创建一条新的任期3的日志,系统就会进入阻塞状态。
这促使我不得不实现了空日志机制,然后按照论文的描述,在一个Leader的成功赢得选举后,立刻向日志中加入一条空日志来启动同步,因为空日志的任期就等于当前任期,所以Leader可以commit它,同时也就commit之前没有commit的日志。
空日志机制听起来简单,但是实际比想象中困难。最大的问题是lab3的测试默认raft和上层应用交流时使用的下标是从1开始连续的。所以我们不能直接将raft中的下标直接作为applyMsg的下标,因为存在空日志会让下标不连续。
所以我不得不又引入了一个新的中间转换层,将Raft和上层应用之间交流的下标称为externalIndex,而Raft内部的下标称为internalIndex。每次要交流下标时都要做一次转换,转换方式我只想到了一个笨方法,遍历当前本地的日志,剔除空日志。虽然听起来很笨但实现起来也很麻烦,因为要考虑snapshot机制,为此我还无法避免地去修改了InstallSnapshot RPC的argument。
虽然这个问题在后续更换了KV-server的实现后就自然而然地消失了(最开始的实现server在重试时会等待某个特定Index的日志commit,这种等待导致了系统的阻塞,后面实现中每一次重试都创建一条新的日志,就自然不会遇到这种问题了),但还是作为一个重要机制保留下来了,毕竟这是论文中也有提及的做法。
使用无锁队列发送applyMsg
大概是因为实现的不同,我的kvserver相比lab3的测试框架代码更容易触发带锁apply时可能的死锁。具体就是在实现InstallSnapshot时,为了保证snapshot万无一失地发送到了上层应用然后再开始apply日志条目,我选择带锁进行apply,并且错误地认为这样做不会造成死锁问题(额,至少在lab3的测试中这个问题几乎没有发生过)
具体的触发流程是这样的:(在修改后的lab3回顾中也有提及,这里直接照搬了)
- Raft收到InstallSnapshot RPC, 获取的
rf.mu锁,随后向管道发送snapshot(未解锁),直到上层接收前不会解锁 - 上层应用同时受到一个客户端请求,获取了
kv.mu锁, 上层应用处理客户端请求时调用Raft.Start,该函数尝试获取rf.mu,但该锁被1获取 - 上层应用的apply线程在处理上一个applyMsg,尝试获取
kv.mu锁,但该锁被2获取,在处理完该applyMsg之前不会接收snapshot,这时1就一直处于阻塞状态
这样的循环等待导致了死锁(之前apply能不触发这个死锁是因为我用了一个tricky的方式,在管道发送前解锁,然后在完成后上锁)
这些问题指向了一个最终解法,先将所有待发送的applyMsg在持有锁的状态下放入一个队列,然后由该队列在无锁条件下进行发送
原本也想使用带缓冲的管道作为队列,但是管道有限的大小和自带的阻塞属性太过危险,所以就自己实现了一个队列。底层用的是slice,当然用list或者直接用官方库才是正解,不过如果对效率不怎么在意的话就先用slice做一下可行性了。
type ApplyQueue struct {
queue []ApplyMsg
mu sync.Mutex
}
func (aq *ApplyQueue) Enqueue(val ApplyMsg) {
aq.mu.Lock()
defer aq.mu.Unlock()
aq.queue = append(([]ApplyMsg)(aq.queue), val)
}
func (aq *ApplyQueue) Dequeue() (ApplyMsg, bool) {
aq.mu.Lock()
defer aq.mu.Unlock()
if len(aq.queue) == 0 {
return ApplyMsg{}, false
}
ret := aq.queue[0]
aq.queue = aq.queue[1:]
return ret, true
}
func (aq *ApplyQueue) Front() ApplyMsg {
aq.mu.Lock()
defer aq.mu.Unlock()
return aq.queue[0]
}
func (aq *ApplyQueue) Size() int {
aq.mu.Lock()
defer aq.mu.Unlock()
return len(aq.queue)
}
func (aq *ApplyQueue) Clean() {
aq.mu.Lock()
defer aq.mu.Unlock()
aq.queue = make([]ApplyMsg, 0)
}
这个Dequeue一开始也想做成C++标准库那样不带副作用,不过那个不太符合我的需求,现在这个实现会返回一个bool值来表示是否操作成功,这样这整个操作就是原子的,只有yes or no两种情况。如果不返回ok的话,就无法处理在一些并发情况下可能会出现的:前面的size检查显示大于0,但是到dequeue时因为调度问题size已经变成0了。
go提倡的“do not comunicate by sharing memory; instead, share memory by communicating.” 虽然真的很酷,但要用好管道对于我这种半吊子就学过一个下午go的人来说真的很困难。管道自带的阻塞特性感觉总是成为我不想碰它的原因。因此我的实现一股子C风格,几乎没有使用像select这样的高级功能。
将以计时器为主的轮询改为使用条件变量
在原始的Raft的实现中,只有同步日志是使用条件变量来控制的,而其他的过程,比如commit检查,apply检查等都通过定期的轮询(基本是10ms)来检查状态是否变化。这样做整个系统也能work,不过10ms的定期轮询看起来可优化空间很大(实际上之前甚至是30ms),如果有些变化能够被负责的线程马上察觉到,想必效率会有很高的提升。
降低轮询的等待时间是一个思路,不过更正确的想法是使用条件变量
注意到这些长期运行在后台检查状态变化然后做出相应行为的线程有一定的关联性。
比如日志完成同步后进行commit check,commit check完后进行apply check,apply check完之后进行实际的发送(前面提到的无锁队列,显然也是在条件等待)
条件变量正是被设计为用来应对这种情况的。
为此我们引入这些条件变量:
// Cond
// To avoid livelock, signal these conditon variables when heartbeat and Kill()
syncCond sync.Cond // signal every time log changes
commitCond sync.Cond // signal every time matchIndex changes
enqueueCond sync.Cond // signal every time commitIndex changes
applyCond sync.Cond // signal every time applyQueue changes
每一个条件变量都绑定到raft的大锁上,在一个操作的结束时对下一个cond调用signal,具体的时机如同注释所说。
为了避免某一个cond因为某些原因丢失了,我还在每次heartbeat时主动调用所有条件变量的signal,在raft被kill时也对所有的条件变量发送signal,以此让在等待的线程能够注意到raft已经死亡从而主动退出线程
算是个人认为设计的比较好的一部分(虽然其实hints中提示了可以使用条件变量)
KVRaft
在梳理完对Raft的修改后,总算可以正式开始记录下KVRaft的实现了。总体来说不算很难,感觉这个lab的设置更像是对lab3的进一步检验,而实现一个良好运行的KV server反而是更不重要的部分
Client
在写Server端实现之前先讲讲相对简单的Client端实现
客户端(准确来说是实际应用与服务端交流的中间人)的结构体定义如下:
type Clerk struct {
servers []*labrpc.ClientEnd
id int64
leader int
reqNum int64
}
其中id为随机获取的,因为我们没有像zookeeper这样用于全局交流的组件,int64的随机几乎不可能出现相同id。leader记录了上一次成功完成了client端操作的server,以此方便下次可以直接向已知的leader发送请求。reqNum是用于同步的重要机制,它在客户端每次被调用Get(),Put(),Append()时单调递增,作为该次操作的唯一ID,Server端根据比对reqNum来确定每一条apply的日志是否是过时的。
至于Clerk的实现没有什么奇怪的做法,就是不断尝试向每个Server发送RPC,然后根据回复决定是否要继续发送。因为我们假设任何时刻对于一个Clerk只会存在一个操作,所以在完成操作前会无限重试直到完成。
我选择的也是简单的串行发送,因为在绝大部分稳定的情况下,只要向上一次成功的Server再次发送请求即可,它大概率还是Leader。如果不是的话就顺序地串行地向其他Server发送,直到受到最新的Leader的肯定回复。因为RPC框架做好了超时处理,我们只需要简单地检查ok是否为真就可判断有无正常通信。
顺便一提,lab4的测试框架居然故意把servers数组打乱了,这时Clerk可能认为自己在向server 1发送请求,但实际处理请求的可能是server 3,不怎么方便Debug。我的做法是让server返回自己的名字,以满足Debug的需要
Server
Client只要简单地发送请求即可,而Server端要考虑的事情就多了。
通用逻辑
首先先做一个架构上的优化,注意到Get(),Put(),Append()三种请求中,其实工作逻辑是一样的,唯一的区别就在于参数和返回值以及日志apply时对状态机的影响不同,其他的逻辑完全可以共享(根据hints,get请求也进入日志以保证当前响应的server是majority的leader)。好在go的泛型虽然不是很好用,但足够我们来实现通用的逻辑了。
定义这样的接口,和通用的处理函数:
type GenericArgs interface {
getId() int64
getReqNum() int64
}
type GenericReply interface {
setErr(str Err)
getErr() Err
setServerName(name int)
}
func (kv *KVServer) handleNormalRPC(args GenericArgs, reply GenericReply, opType string)
好吧,这一堆get,set看着确实很烦人,但我确实没有想到更好的做法了。接着就是为两种参数和两种返回实现这些接口,在handleNormalRPC()中 只需根据opType进行一些分支来处理不通用的部分。好处还是很显然的,只需要实现一套控制逻辑,而不用两侧同时修改了。
数据结构
先不算上Snapshot,Server端使用的数据结构如下:
type Session struct {
LastOp Op
LastOpVaild bool
LastOpIndex int
}
type Op struct {
Type string
Number int64
Key string
Value string // vaild if OpType is OT_Put or OT_Append
ReqNum int64
CkId int64
}
type KVServer struct {
mu sync.Mutex
me int
rf *raft.Raft
applyCh chan raft.ApplyMsg
dead int32 // set by Kill()
maxraftstate int // snapshot if log grows this big
persister *raft.Persister
mp map[string]string
ckSessions map[int64]Session
logRecord map[int]Op
confirmMap map[int]bool
lastApplied int
}
说实话有点复杂,不过下面将慢慢说明各个数据结构的用途。
Session用于维护Server和Clerk之间的会话关系,维护上一个Op相关的信息,在处理applyMsg时Server根据Session中记录的情况来判断是否要应用这个applyMsg。在最开始的设计中Session还会维护当前Op相关的信息,不过后面发现不等待某个Op的apply做起来更简单也不会陷入阻塞,就移除了当前Op相关的信息。
Op就是我们要向Raft.Start()传递的参数。Op要区别于Clerk中的单次Operation,现在看来Op可能称为Entry会更合适,因为每一个Op都在Raft的日志中有一条对应的条目。Clerk的单次操作(Get,Put,Apppend)的RPC每次发送到Server时都会创建一个Op,也就是说Clerk的每一次重试都会创建一个Op,这些Op都有相同的reqNum,在apply时我们通过Session记录的上一次成功的Op的信息来排除具有过时的reqNum的Op。
Op.Number是在Op创建时生成的随机数,其主要用途是检查进入Raft和从Raft出来的数据是否是相同的,以此来检测该Op是否成功commit,如果出入都相同,说明该Op成功commit了,如果出入不同,则说明因为一些原因该Op未能达成共识,原本为该Op的Index处有了别的Op。
至于Server主体的数据结构,图方便就都使用map来记录了,虽然slice也可以,不过经常容易out of range。其中mp是状态机的核心,维护KV服务;ckSessions用于维护ckId对应的Session;logRecord用于记录从Raft中成功apply的Op;confirmMap用于记录被Clerk确认了不再需要的信息,主要用于定期删除logRecord以减少内存开销,其工作方式是在每次更换Session.LastOp时添加条目[上一Op.Index, True];lastApplied用于检查applyMsg是按顺序递增的
其实在解释完这些数据结构之后,基本就把Server端的实现讲完了。不过还是有一些小细节可以讲讲。
请求处理
当收到来自Clerk的请求时,Server根据请求中包含的CkId尝试找到对应的Session,如果存在Session则进一步检查Session的LastOp的reqNum是否和请求参数中的reqNum相同,相同则检查该LastOp是否已完成,完成的话就可以直接回复操作成功。
Server没有发现成功的话就开始一个新的Op,注意Raft.Start()可能会返回错误,这时就要回复失败,让Clerk尝试下一个Server。
等待请求完成
当开始了一个新的Op,Server会尝试等待该Op在集群中达成共识,该功能由以下函数实现,签名为:
func (kv *KVServer) waittingForCommit(op Op, index int, args GenericArgs, reply GenericReply, opType string)
该函数周期地以键为index访问logRecord,如果还不存在就等待下一个周期。如果存在则拿出logRecord记录的值,这里称为finishOp;通过检查finishiOp和参数中的Op的Number属性来确定是否是同一个Op。如果是则万事大吉,直接回复成功,如果不相同则说明因为Raft底层的一些行为导致了该Op没有达成共识,该index被别的Op代替了,那么就回复失败。
如果在一定时间内都没有在logRecord中找到对应index的值,则认为commit超时,返回失败,让Clerk重试。
处理applyMsg
参考lab3的测试代码,使用类似如下的代码接受applyMsg:
for applyMsg := range kv.applyCh {
if applyMsg.CommandVaild {
// 处理日志entry的apply
} else if applyMsg.SnapshotVaild {
// 处理Snapshot的apply
}
}
处理日志entry的apply比较简单,首先向logRecord加入该Op,让waittingForCommit()能够检查到该Op的apply,接着更新lastApplied。
下一步挺重要的,Server检查该Op对应的ckId的Session,如果Session中记录的LastOp的reqNum大于等于该Op的reqNum,则认为刚从Raft中获取的Op是一个过时的Op,所以放弃应用这个Op。
接着更新一下session,把lastOp更新为刚获取到的Op,同时将上一个LastOp的index在confirmMap中标记为true,代表该op不再需要(Clerk是串行请求Server的,而Raft保证每次start返回的index都是递增的,所以更高的index表示一定是更新的请求,那么处于同一个session的更低index的Op就显然就可以认为不再需要,因为不会有waittingForCommit()等待这个更低的index了),在confirmMap中标记的index在创建snapshot时会被从logRecord中删除,以此减轻内存开销。
Snapshot
沟槽的万恶之源snapshot,虽然最后的解决方案看着简单,但是为了调对snapshot还是花了不少时间。
制作Snapshot
参考lab3的测试代码,在每一个apply完成之后检查是否满足Snapshot创建条件。接着按照前面描述的,根据confirmMap删除logRecord和confirmMap中的条目,以减少内存占用。
然后制作Snapshot,我认为Snapshot要包含的数据为ck.Mp和ck.Sessions:
type Snapshot struct {
Mp map[string]string
CkSessions map[int64]Session
Maker int // for debug
}
为什么这两个数据能够保证恢复状态机?
首先肯定要保存KV键值对,不然Snapshot就没有意义了。然后就是ck.Sessions,根据前面的描述,它用来维护和客户端的情况,主要维护的是某个客户端上一个完成的Op。当崩溃重启后,Clerk和Server第一次通信时,也能够通过检查ck.Sessions包含的LastOp的reqNum是否和请求中的相同来确定请求的Op是否完成,所以不会重复执行。因为Snapshot的制作总是在完成了一次apply后,也就是(可能)更新完了map和session后,所以可以保证两者的关系是对应的。
应用Snapshot
这个倒是没啥好说的,加锁然后更换Snapshot中的mp和sessions,同时更新lastApplied为applyMsg.SnapshotIndex。
总结
和开头说的一样,这个月状态一般,繁杂琐事有些多,这个lab4也磕磕绊绊写了快半个月,大部分时间也都花在处理Raft遗留的问题上,在开始的时候有点过于自信自己的Raft实现,把错误都归咎于Server写的不好,所以也花了很多无用的时间在排查Server的问题。事后也证明Server本身的实现其实很简单,虽然不知道为什么lab 4A测试的占用有些异常的高,也许是哪个地方疏忽了,也有可能是本身测试就很暴力。
不管怎么说,这门课程到这里就快接近尾声了,只剩下一个lab5没有完工。未来可期。。。