
MIT-6.5840-ShardKV
该课程系列的最后一个lab,个人认为难度非常高。事后来看似乎也就那么一回事,但找到正解的过程真的很困难,耗费了大量的时间。临近期末,有很多事要处理,没有将百分百的精力花在这上面,前后大概用了十天的时间完成了该lab,这里也抽空趁记忆没有模糊之前赶紧草草记录下实现的回顾。
之后应该会写一个对于整个课程的回顾,但估计得等到明年了,接下来不得不把时间浪费在应付学校课程上了。
最后的实现方案成功通过了包括challenge在内的所有测试10000次,虽然在我看来这个实现方案有一些说不清的不和谐感,但既然测试通过了那我也不管那么多了。
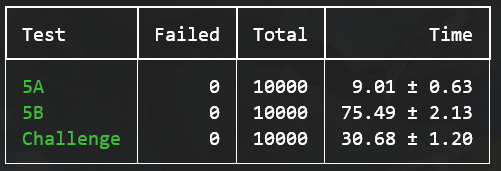
正如前面所说的实现起来其实也就那么一回事,因为说到底都是基于Raft的一些应用构建罢了。
等所有的lab完成到这一步,应该要对自己的Raft有百分百的自信。幸运的是至少我的Raft在经过lab4的锤炼之后变得足够健壮,在这个lab中我完全没有考虑过Raft的错误,将注意力集中到应用层的结构上,这节省了我的大量精力。所以一定要保证Raft的正确性,前面的lab的测试至少要测试10000次才可以说是正确。
Part A: The Controller and Static Sharding
实现一个配置控制器,本质就是一个KV server。
跟Hint说的一样,这部分基本就是照搬lab4的实现,唯一值得说的就是rebalance算法的设计
Rebalance
当一台机器加入,离开或者移动时,要对现有的shard进行重新分配。为此要设计一个分配算法来保证move as few shards as possible to achieve that goal
为了想这个分配算法说实话花了不少时间,不过最后的做法其实相当蠢。
虽然直接给出代码讲解会更简单,但是出于学术诚信(实验的仓库应该之后会设为私有),这里尽量以讲解思路为主。
在完成一次更新后,重新平衡之前,两个config之间的唯一区别在于Config.Groups不同,然后进入rebalance:
-
首先找出在新的config中不属于任何gid的shard,我们称为
orphanShards这步通过检查在
oldConfig.Shards记录的gid是否在newConfid.Groups中存在来实现。 -
同时记录在新旧config中不变的shard
显然除去
orphanShards以外就都是不变的shards。将这个结果保存在一个由以下结构体组成的切片GSs下type GS struct { // Gid and Shards Gid int Shards []int } GSs := make([]GS, 0)每一项记录一个Gid对应的Shards,之后我们会频繁修改该集合来实现平衡
-
接着排序
GSs正如Hints所说,go的哈希表和C++的unordered_map一样是一个无序的实现,所以在不同的机器上相同记录的map在遍历时的顺序可能不同,这导致
GSs在不同的机器上的记录可能不一致,这显然会导致最后的rebalance结果不同。所以我们对
GSs先根据gid进行排序,然后再对内部的GS.Shards也进行一个排序,以此保证在进入下一步之前所有机器是一致的。 -
通过简单的遍历找出哪两个Gid拥有的Shards最少和最多
因为
NShards只有10,所以这里直接用遍历来获取了,只要前面保证了GSs的有序就可以保证这里获取的最少和最多在所有机器上都是相同的, -
如果
orphanShards还有剩余即不为空,则将其的最后一个取出加入到拥有最少的Shards的Gid的Shards中,然后重复第4步。 -
如果
orphanShards没有剩余,则检查最多的Shards和最少的Shards相差是否大于1,如果大于1则将最多Shards中的一个移动到最少的Shards中,然后重复第4步。 -
如果相差小于等于1说明已经重新平衡完毕,此时将
GSs中记录的最终结果应用到NewConfig上后结束平衡。
非常简单的算法,但我想我应该思考了一两个小时才想通。
Part B: Shard Movement
非常棘手的一部分,虽然框架还是延续lab4的做法,但区别在于这次我们要让各个服务器之间进行直接的通信来实现移动。
总览
先来看下为了实现这个我们针对lab4做了哪些修改,以下是数据结构的区别
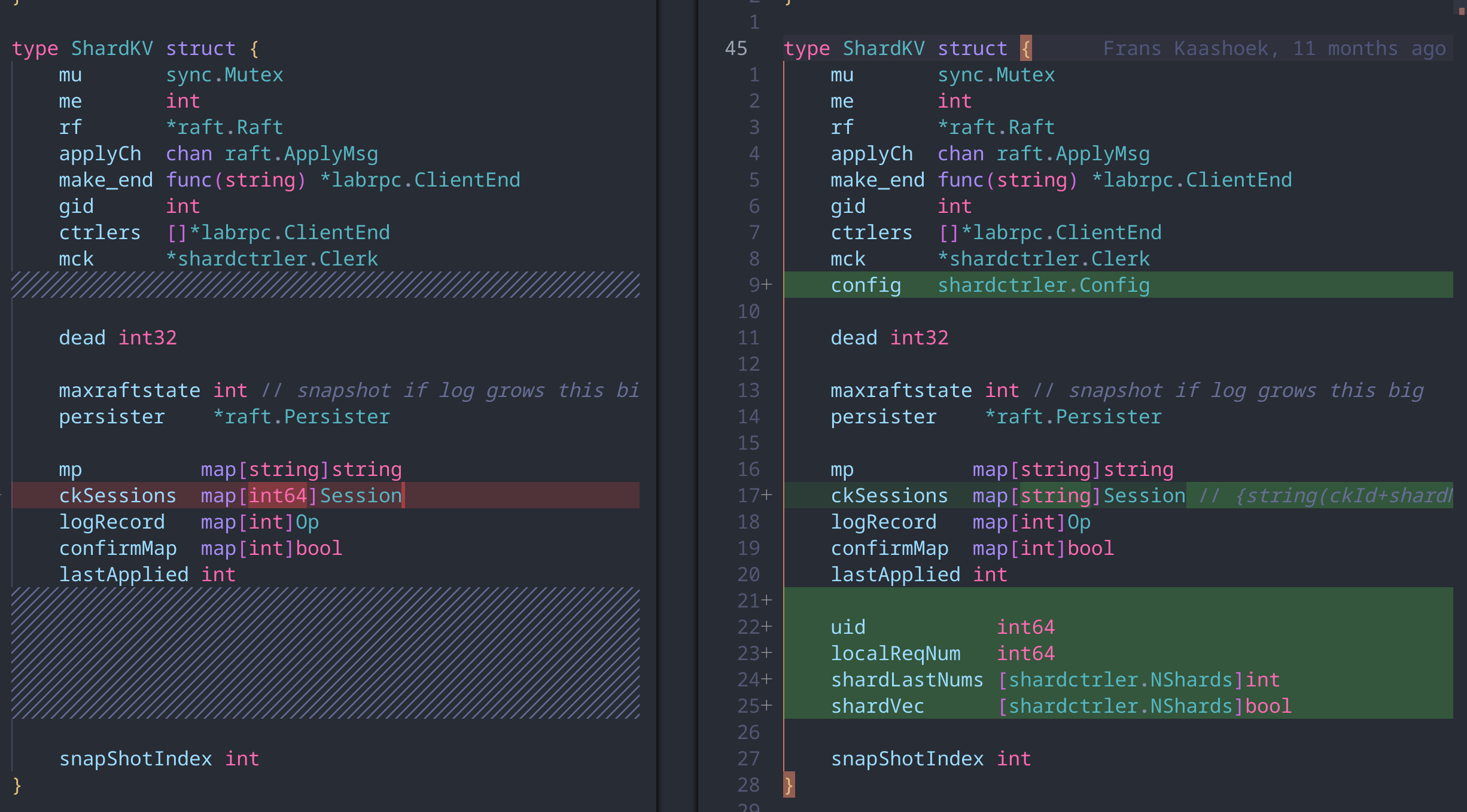
和lab4一样,在处理RPC时会按照以下流程进行
- 上层服务接收到RPC请求
- 上层服务将RPC请求加入Raft
- 当大多数的Raft拥有该条日志,应用该日志
- 根据日志中的信息,上层服务更改自身状态
- 回复RPC请求
通过这一流程保证状态更改的一致性
新的RPC
服务端所有的RPC如下
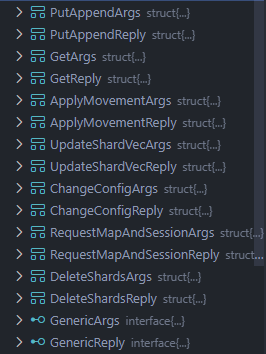
多了以下几个,以工作流中的调用顺序进行排序
| RPC | 功能 | 备注 |
|---|---|---|
| UpdateShardVec | 更新一个Group允许处理的Shard的向量 | 只作为 “本地RPC”,将其称为向量单纯是因为比较帅 |
| RequestMapAndSession | 向一个Group请求要移动的Map和Session | 在一次Shard移动中由接收方发起,发送方响应 |
| ApplyMovement | 将RequestMapAndSession收集到的信息应用于整个Group | 只作为 “本地RPC” |
| DeleteShards | 向一个Group发起删除某些Shards的建议 | 在一次Shard移动中由接收方发起,发送方响应 |
| ChangeConfig | 将配置更改的信息应用于整个Group | 只作为 “本地RPC” |
“本地RPC” 在这里指那些由一个Group的Leader发起,同时也由该Leader响应的RPC。使用这个本地RPC的原因是为了复用处理正常RPC的代码,让一些变化在组内保持一致,比如说更新Config在完整进入Raft之后然后再apply就能保证所有机器上的状态更新一致。这是我认为该lab最为关键的原则:让所有的状态改变进入Raft
在简单地列出这些RPC之后其实整个工作流程就已经明朗了
在处理RPC上我们沿用lab4的那套泛型方案,使用一个通用的代码处理RPC
只要满足以下接口即可复用通用代码
type GenericArgs interface {
getId() int64
getReqNum() int64
getKey() string
}
type GenericReply interface {
setErr(str Err)
}
func (kv *ShardKV) handleNormalRPC(args GenericArgs, reply GenericReply, opType string)
接下来就按照工作流来一一说明下新加入的RPC
UpdateShardVec
type UpdateShardVecArgs struct {
Id int64
ReqNum int64
ConfigNum int
NewVec [shardctrler.NShards]bool
}
type UpdateShardVecReply struct {
Err Err
}
该RPC最开始的命名为SetPreConfig,影响的是字段ShardKV.preConfig,是为了Challenge 2引入的一个RPC。它会在进行一个Config更改之前预先设置一个临时的Config,preConfig永远比ShardKV.Config领先或者相同。
在接受到一个客户端请求时,会检查preConfig和当前的Config来确定是否要回复。比如在Challenge 2A中要求对Config更改中不变化的Shard保持回复,那么只需要检查preConfig和当前的Config是否同时拥有该Shard即可实现。
之所以将其更改为现在的形式主要是为了更精细的控制,我的实现中Group不是根据当前的Config来决定是否要回复,而是检查类似于中断向量表的ShardKV.ShardVec来决定是否回复。
这在实现Challenge 2B时十分有用,因为其要求响应已经完成移动的Shard。这时只需要在成功完成ApplyMovement时顺便更新ShardKV.ShardVec来解锁对这些Shard的访问即可。
一旦Server检查到了Config的变化,它首先检查新旧Config中有哪些是不变的,创建一个新的ShardVec,然后通过该RPC将新的ShardVec应用到所有组内的大多数机器上。然后进入到Shard Move的环节
RequestMapAndSession
type RequestMapAndSessionArgs struct {
Gid int
Me int
Shards map[int]bool
ConfigNum int
}
type RequestMapAndSessionReply struct {
Err Err
Mp map[string]string
Sessions map[string]Session
}
该RPC以需要接受的Shards作为参数发送给持有这些Shards的Group,而接受方以对应的Map信息还有关于这些Shards的Sessions进行回复。关于Session的话题后面会详细展开。
该RPC会在配置编号不匹配的情况下回复ERR_LowerConfigNum,拒绝回复,要求接受者等待发送者的Config更新。
ApplyMovement
type ApplyMovementArgs struct {
Id int64
ReqNum int64
Mp map[string]string
Sessions map[string]Session
Config shardctrler.Config
Shards map[int]bool
}
type ApplyMovementReply struct {
Err Err
}
将收集到的信息进行应用。
和前面说的一样,将其设计为RPC是为了重用处理普通RPC时的逻辑,让更改进入Raft,以保证所有服务器状态更改能够应用到大多数的服务器。
DeleteShards
type DeleteShardsArgs struct {
Id int64
ReqNum int64
Shards map[int]bool
ConfigNum int
}
type DeleteShardsReply struct {
Err Err
}
在一次Shard移动中由接收方发起,用于建议发送方删除已经成功接收了的Shards
之所以说是建议,这是因为网络的不可靠性以及一些时延上的问题,该RPC可能在Config变化多次之后延迟抵达,关于这些内容后面我会进行更详细的讨论
ChangeConfig
type ChangeConfigArgs struct {
Id int64
ReqNum int64
OldNum int
NewNum int
Config shardctrler.Config
}
type ChangeConfigReply struct {
Num int
Err Err
}
用于更新Group的Config
工作流
在说明完这些RPC之后,工作流的完整图景就已经完成了。
所有的服务器在启动后会启动一个协程,如果为Leader则定期拉取最新的Config,如果有更新则尝试更改Group的Config。
更新过程分为三个阶段:更新ShardVec,移动Shards,更新Config
大致代码如下(略去了大部分的控制代码)
注意不能直接变化到最新的Config,每次Config变化只能增加一,这样才能正确同步状态。
-
阶段一:更新ShardVec
该阶段综合要更新的Config和旧Config,决定出哪些Shard是不移动的,哪些是暂时不允许访问的,然后更新ShardVec。该机制主要是为了Challenge2Unaffected而实现的,该Challenge要求服务器能够响应那些在Config变化中不受影响的Shard请求。
-
阶段二:移动Shards
最核心的一个阶段,具体的机制后面详细介绍。总之在这个阶段服务器要完成Shard的移动,并且在途中完成ShardVec的更新,允许对已经完成移动的Shard的访问请求,以此来完成Challenge2Partial的要求。
-
阶段三:更新Config
在确定了所有要移动的Shards移动成功后进行Config的更新。
始终要记得任何对服务器状态的更改(比如ShardVec的更新,Config的更新等)都要进入到Raft中以此保证组内的一致性。
func (kv *ShardKV) pollConfig() {
for !kv.killed() {
if _, isLeader := kv.rf.GetState(); !isLeader {
time.Sleep(100 * time.Millisecond)
continue
}
latestConfig := kv.mck.Query(-1)
kv.mu.Lock()
for kv.config.Num < latestConfig.Num {
// ... some code...
nextConfig := kv.mck.Query(kv.config.Num + 1)
// phase 1: update ShardVec
kv.handleNormalRPC(&updateShardVecArgs, &updateShardVecReply, OT_UpdateShardVec)
// phase 2: move shards
kv.moveShards(kv.config, nextConfig)
// phase 3: change config
kv.handleNormalRPC(&changeConfigargs, &changeConfigreply, OT_ChangeConfig)
}
kv.mu.Unlock()
time.Sleep(100 * time.Millisecond)
}
}
ShardKV.moveShards()作为最为重要的一部分单独说明:
主要分为四步:
-
综合旧Config和新Config中的信息,找出要向哪些组接收哪些Shards,确定出
receiveFrom集合。 -
使用收集到的信息并行地向有关的组发起
RequestMapAndSession,获取于要移动的Shard有关的键值对和Session信息。 -
一旦有
RequestMapAndSession接收到回复后启动ApplyMovement来更新状态,在处理ApplyMovement时要更新ShardVec来解锁已完成移动的Shard的访问功能。 -
等待所有的Apply完成后向其他组发起
DeleteShards
代码已裁剪,删除了一些控制条件和重试的循环,只保留大意。
func (kv *ShardKV) MoveShards(oldConfig shardctrler.Config, newConfig shardctrler.Config) bool {
//...check before moving
// which shard should receive from. (gid -> {set of needed shards})
receiveFrom := make(map[int]map[int]bool, 0)
// Collectting...
// ...some Code to fill receiveFrom
wg := sync.WaitGroup{}
sendApplyMovementLock := sync.Mutex{} // only allow single applyMovement at a moment to avoid ReqNum conflict
applyMovementFail := int32(0)
for gid, shards := range receiveFrom {
wg.Add(1)
go func(gid int, shards map[int]bool) {
defer wg.Done()
//loop.....
ok := srv.Call("ShardKV.RequestMapAndSession", &args, &reply)
if ok && reply.Err == OK {
sendApplyMovementLock.Lock()
kv.ApplyMovement(&moveArgs, &moveReply)
sendApplyMovementLock.Unlock()
return
}
// ... not ok, or ErrWrongLeader
// handle error...
}(gid, shards)
}
kv.mu.Unlock()
wg.Wait()
// handle error...
// Send DeleteShards only after ApplyMovement succeed
// **SUGGEST** to delete, not force delete
for gid, shards := range receiveFrom {
wg.Add(1)
go func(gid int, shards map[int]bool) {
defer wg.Done()
reply := DeleteShardsReply{}
ok := srv.Call("ShardKV.DeleteShards", &args, &reply)
if ok && reply.Err == OK {
return
}
// ... not ok, or ErrWrongLeader
// handle error
}(gid, shards)
}
wg.Wait()
kv.mu.Lock()
return true
}
一些实现细节
下面讲一些实现上的细节,大部分是遇到的坑。
大部分是通过查看git log来回忆的
为客户端在每个Shard的访问上单独分配一个ID
在ShardKV.handleNormalRPC()中,标识每个客户端访问的RPC与lab4不同,是使用如下的方式计算出来的
uniKey := strconv.FormatInt(args.getId(), 10) + strconv.FormatInt(int64(key2shard(args.getKey())), 10)
也就是为同个客户端对不同Shard的访问使用不同的Session进行控制
这是为了实现Shards移动引入的机制。因为如果不这么做,在移动时移动Session后会将导致操作在并发条件下不可线性化
通过这个机制,在交换Shards时只交换与要交换的Shard相关的Session,这样就不会出现重复操作的问题
相关的commit message(塑料英语随便看看):
lab5-fix: fix error “history is not linearizable”
Now different client operations on different SHARDS of same group will have an unique session with unique ID “{ckid}+{shardNum}”.
There used to be only “{ckid}”, which made history not linearizable in some concurrent conditions.
Each group will exchange those session when config changes
Now pass all tests of Test5B for 200 times.
Errors still exist (1/200), but I believe they are caused by other reasons.
优先检查是否Leader
在收到一个请求之前,在检查请求是否属于该Group管理之前要先检查是否是Leader。
虽然听起来很常规,但是为了查出这个Bug确实花了我不少时间。
当时的commmit message是这样写的:
lab5-fix: fix a timeout error
Now server will do checking leader before checking group in ShardKV.handleNormalRPC().
Because client will BREAK the request loop once a server reply with ERR_WrongGroup.
Trace back:
If server[100][0] is not at latest config and not a leader(which means it wouldn’t try to update config, see ShardKV.pollConfig());
Then client asks to server[100][0] and server[100][0] replies ERR_WrongGroup.
The client BREAK the loop to try to re-request latest config.
At next time client will also try to ask server[100][0] FIRST, but server[100][0] will never poll latest config if it’s not a leader.
So there will be an infinite loop if we don’t check isLeader before checking group.
大概就是如果不先检查leader而直接检查shard权限就会陷入无限循环
为每一个Shard记录获取时的版本号
在实现中有一个数组shardLastNums记录了该组在获取到该shard的管理权时的版本号。这样做可以很方便地避免因为RPC延迟造成的过时请求。
如果一个删除请求的版本号低于组内获取到该Shard管理权的版本号,就可以判定这个删除请求过时了,可以忽略该请求,避免删除一个已经有效的Shard。
同时如果有一个applyMovement的版本号也低于获取到该Shard管理权的版本号,也判定该更新请求过时。这样可以避免在实现Challenge2Partial后,滞后的更新请求导致新的内容被覆盖的情况。
总之引入这样一个数组记录之后能够很方便地排除很多错误情况。
本地RPC的ID
在实现中,本地RPC的ID也是一个一直困扰我的问题。
所谓“本地RPC”是那些由服务器集群自己在组内调用的RPC,这就必须要跟普通客户端的RPC区分开来。比如客户端的请求,如Get,Put,Append这些都要检查组是否持有该Shard。但是“本地RPC”不需要考虑这个问题,需要给于一些特权。同时它们的Unikey的生成就不需要Shard的参与了。
最开始时统一全部使用-1来标识本地RPC,这样做的问题是如果Leader崩溃了,新产生的Leader会对当前的Session产生一些迷惑,因为ReqNum只有Leader才会更新。
比如说在一个组内,当前的Leader进行了很多次本地RPC,ReqNum已经更新到了100,而其他的Follower因为不进行本地RPC,所以ReqNum还是0。同时组内关于ID=-1的Session的ReqNum也是100。这时Leader崩溃,新产生的Leader以ReqNum=0对组内进行本地RPC,但是组内关于ID=-1的Session的ReqNum是100,显然会拒绝该看起来是“过时的”的请求。
所以最后的实现是为每一台服务器都使用一个负的随机ID,使用负来代表是组内的请求,随机ID避免了上述情况的发生。
还有一个问题是本地ID是否要持久化,实践的经验是不需要也不可以持久化。在Raft中,持久化要依赖于Snapshot,但是Snapshot又会在组间自由交流,导致组内有了相同的ID,又造成了上述情况的发生。
MoveShard时,一边收集信息一边Apply
在先前的实现中,出于实现方便,MoveShard的步骤是先收集全部需要的信息,然后再开始Apply。这样做在最后一个Challenge之前都工作的很好。
最后一个Challeng要求在Config更改中,允许那些已经完成移动的Shard的访问。测试程序的做法是让拥有某个Shard的组断联,其他正常。如果保持原来的做法,先收集再Apply,就会一直在收集等待。所以我们要实现的是一边收集信息,一边Apply。一旦一个Shard已经收集到了足够的信息,立刻发起Apply。
泛型的使用
有很多代码的逻辑是一样的,所以做成泛型会更好。
与lab4不同,在这里的泛型进行了一些修改,主要是关于Op的修改
因为lab4只需要考虑key,value两种就行,这里我们将所有Op的Arg作为一个泛型存储
type Op struct {
Type string
Number int64
ReqNum int64
CkId int64
ShardNum int
Args interface{}
}
在创建时,我们通过这样的代码创建一个Op
op := Op{
Type: opType,
Number: nrand(),
ReqNum: args.getReqNum(),
CkId: args.getId(),
ShardNum: key2shard(args.getKey()),
}
switch opType {
case OT_GET:
op.Args = *args.(*GetArgs)
case OT_PUT:
op.Args = *args.(*PutAppendArgs)
case OT_APPEND:
op.Args = *args.(*PutAppendArgs)
case OT_ChangeConfig:
op.Args = *args.(*ChangeConfigArgs)
case OT_ApplyMovement:
op.Args = *args.(*ApplyMovementArgs)
case OT_DeleteShards:
op.Args = *args.(*DeleteShardsArgs)
case OT_UpdateShardVec:
op.Args = *args.(*UpdateShardVecArgs)
}
取出Op时,进行这样的操作重新获取到Arg
switch op.Type {
case OT_GET:
getArgs := op.Args.(GetArgs)
// ...
case OT_PUT:
// ...
//...
}
同时还要在RPC框架中注册这些类型
labgob.Register(Op{})
labgob.Register(GetArgs{})
labgob.Register(PutAppendArgs{})
labgob.Register(ChangeConfigArgs{})
labgob.Register(ApplyMovementArgs{})
labgob.Register(DeleteShardsArgs{})
labgob.Register(UpdateShardVecArgs{})
多亏了go还算不错的泛型,只需要做这样一些简单的判断就可以实现重用逻辑
尽可能裁剪Op的存储信息
lab4的实现中,Session将完整保存一份Op
type Session struct {
LastOp Op
LastOpVaild bool
LastOpIndex int
}
type Op struct {
Type string
Number int64
Key string
Value string // vaild if OpType is OT_Put or OT_Append
ReqNum int64
CkId int64
}
这样做当然是没问题的,除了会完整保存一份Op中的Key,Value以外。
然而Challenge 1要求尽可能裁剪存储空间,如果继续保存整个Op,那么你就会发现Snapshot过大,而且超出的大小其实不多(我遇到的是130262 > 117000)
这是因为Op中保存的Key,Value毕竟是String类型,是可以非常大的。
所以更改后的结构如下:
type Session struct {
LastOpVaild bool
LastOpIndex int
LastOpNumber int64
LastOpReqNum int64
LastOpShardNum int
}
type Op struct {
Type string
Number int64
ReqNum int64
CkId int64
ShardNum int
Args interface{}
}
只保留必要的Op相关的信息
总结
虽然实现中感觉十分困难,但回头来看作为最后的一个lab难度上其实不大,Raft的实现的正确性在lab4就已经验证过了,剩下的只需要相信Raft就行。
整个lab5中最麻烦的就是delete的实现,其他其实都很简单。整个lab花费了大概一周多的时间,算是一个平均时间吧。
这样一来6.5840的lab就告一段落了,后续打算把lab改成实际生产可以使用的项目,要做的大概就是把实验框架中的RPC和持久化相关的部分更改一下就行了,这样简历上至少有个还算说的过去的项目了。