
CMU-15445 fall 2024 p1
前言
今年新开一个坑,重学一遍数据库。
虽然拿到了字节基础架构的实习offer,三面面试官也说不太需要强数据库背景,不过是搞数据库的组,要是对数据库一窍不通也说不过去。所以决定重新学一遍数据库,加深一下印象,同时也丰富一下简历吧。
话说回来,基架选手标配的15445和6.824的顺序似乎应该是先做15445再做6.824来着,而且据说应该会更简单一点,但是我个人做起来感觉难度还是有的。
感觉困难的点主要是测试用例不是完全公开的,只提供了一部分的子集。所以只能通过log来慢慢推算测试用例的做法,同时自己也要写一些测试案例。
p1实现大概用了四五天吧,这四五天也没有全身心投入进来,好几次都因为黑盒测试而不想继续下去,不过好在最后还是做完了,在Leaderboard上qps排了43名。这门虽然很热门,但真正有去做project的人并不多,Leaderboard上目前有效的提交也就两百多人,也就是说国内同期认真做过这个project的人其实没有多少。
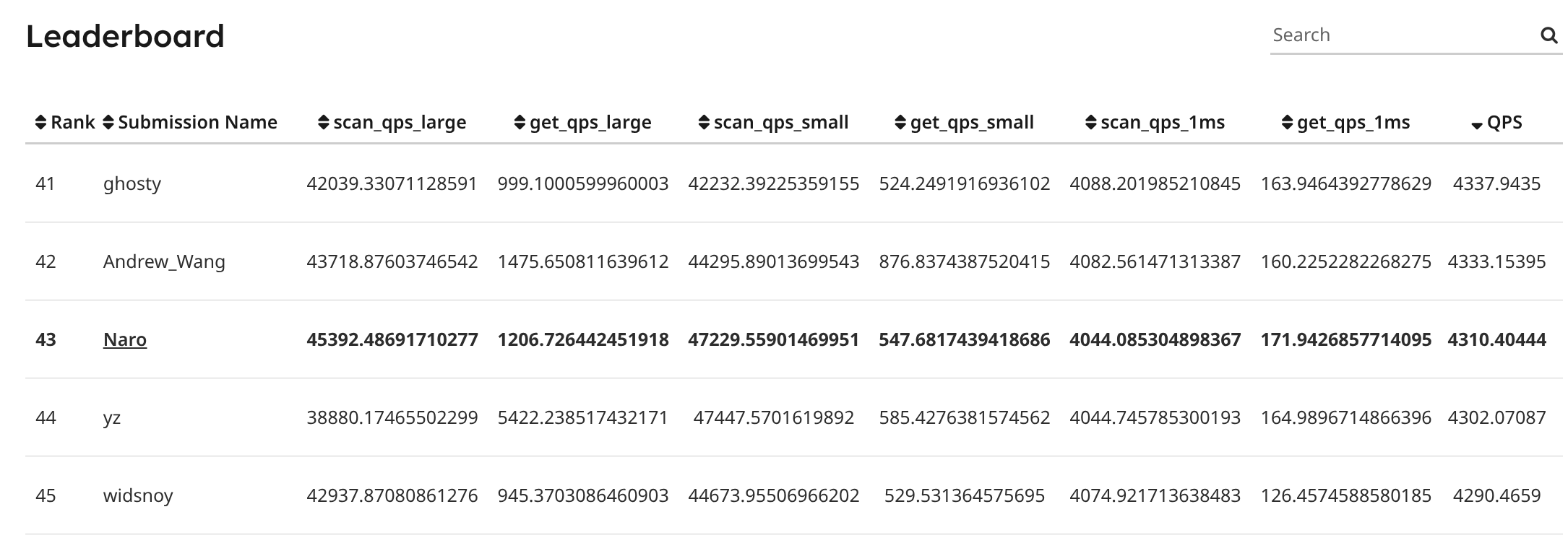
接下来的内容主要讲讲总体上的思路和实现中遇到的小坑,大概不会涉及源代码,毕竟andy似乎非常不喜欢学生公开project的代码。
不过我觉得应该不会有除了我之外的其他人来看这个文章,这篇文章的最主要目的还是给以后的自己来快速回顾用的。
Task #1 - LRU-K Replacement Policy
实现LRU-K替换算法
普通的LRU和K=2的LRU-K倒是有尝试过,这次要做的是更通用的LRU-K
LRU-K总览
LRU-K是LRU的特例化版本,用于解决常规LRU冷数据访问导致热点数据被淘汰的问题。
LRU-K的大致思路就是维护两个LRU,一个为已经达成K次访问的数据,我称为热LRU,一个为尚未达成K次访问的数据,我称为冷LRU。当一个数据在冷LRU中在被淘汰之前被访问了K次,则将其移动到热LRU中。
虽然称为LRU,但是在LRU-K中,不使用双向链表来维护访问先后,而是根据Backward k-distance来决定要淘汰哪一个。所谓的Backward k-distance就是该数据最近的第k次访问的时间戳,这样的访问无法使用双向链表来代表先后顺序,所以只能使用一个有序的数据结构来实现,我选择的是红黑树(std::map)
所以能看到,上述的LRU-K的结构的访问时间复杂度不是O(1),因为一次访问往往要伴随着树的调整,不过在实现了evictable机制之后,访问以及设置为non-evictable的数据的时间复杂度就能达成O(1)
时间戳和两个std::map
我使用两个std::map来分别维护冷LRU和热LRU,其中键都为k-distance,值则为一个节点。然后和正常的LRU一样,使用std::unoredered_map<frame_id_t, std::map<size_t, LRUKNode>::iterator>来维护frame_id到map节点的映射,以提供快速访问。
使用一个size_t变量来维护时间戳,在系统的每次RecordAccess时,递增这个变量作为该次访问的时间戳,同时在节点中记录该次访问的时间戳。这样的历史是通过一个std::list<size_t>来维护,当要进行访问时,往front添加数据,同时删除末尾元素使得历史时间戳记录的长度不超过K。
对于以及达成K次访问的数据,因为我们总是删去末尾元素使链表长度不超过K,所以k-distance就是历史时间戳记录链表的最后一个。
对于还未达成K次访问的数据,指导书里描述的是“ (i.e., the frame whose least-recent recorded access is the overall least recent access).”刚开始时我没有理解这个的意思,以为应该是最近的一次访问,但实际上根据后续的测试要求来看,这个的意思是最不近的一次访问,也就是还是历史时间戳记录链表的最后一个。
访问时如果历史时间戳记录超过了K次,就将节点移动到达成K的map中
当需要淘汰一个数据时,先查看未达成K的map,如果有数据就逐出map.begin()。如果没有的话则只能逐出已经达成K次的map中的map.begin()。
Evictable 和 Non-evictable
没有多复杂,其实就是暂时把node移动出两个LRU队列。我使用std::unordered_map来维护这些节点的frame_id到节点自身的映射,我称为non_evictable_record。
当一个node被移动到non_evictable_record后,对该node的访问就总是O(1)了。在进行访问时,依次先检查non_evictable_record,然后检查热LRU队列,接着再检查冷LRU队列。因为buffer pool manager在使用一个数据时总是要先pin,也就是将其设置为non-evictable,所以总体的效率其实并不会低于普通的LRU,同时还能避开冷数据将热数据淘汰的情况,算是一个非常聪明的设计,也难怪会被众多数据库系统采纳。
Task #2 - Disk Scheduler
这个模块属于简单的实现非常简单,但是优化的空间非常大的那种模块。
一个最简单的实现就是简单的往Channel里面丢数据,然后让工作线程直接处理就行。要说最大的障碍就是之前没用过c++的promise和callback来进行并发控制,小看了一会reference就会了,其实就是个小型的channel。
不过如果要真正优化的话,其实会非常复杂。比如在操作系统书上可以学习到的将多个磁盘IO捆绑成单次的IO。这些黑科技才是快速的原因,不过我不打算搞的那么复杂,所以就只用简单的实现了。
Task #3 - Buffer Pool Manager
最后要将前面的实现结合起来,组成一个buffer pool manager
本身BPM的结构并不复杂:由一个数组维护frame,一个哈希表维护Page ID到frame ID的映射。在需要读取一个页面的时候创建一个PageGuard,然后返回这个PageGuard即可。
所以主要的复杂度在PageGuard的实现上。
PageGuard
PageGuard以RAII的方式保护一个页面,其保证在创建完该PageGuard之后,直到该PageGuard被析构,都可以保持该Page的Read/Write功能的安全性。
初始化
初始化是PageGuard的第一个关键的部分,在构造函数中,PageGuard需要将frame设置为Pinned,防止其被lru_k_replacer淘汰,同时还要获取该frame的读写锁,避开在存在有效的ReadPageGuard时获取了WritePageGuard。
初始化的关键在于搞清楚获取资源的顺序,一旦顺序错误,就会出现问题,我就是因为这个的顺序错误排查了很久。
正确的顺序是
-
在持有BPM大锁的情况下进入PageGuard的构造函数。
这样做保证在同一时刻只有一个Frame在进入了PageGuard的创建,避免在创建过程中Frame被更改的情况。
-
接着在持有BPM大锁的情况下,将该Frame的pin_count加一,并将其设置为non-evictable。
这一步骤保证了在接下来释放BPM之后,该Frame不会因为页被驱逐而变化。
-
释放BPM大锁,尝试获取该Frame的读写锁。
这一步释放了BPM大锁,然后才去尝试获取Frame的读写锁,主要是为了避免出现死锁。
考虑这样的一个情况(其实就是DeadLockTest里的Case):线程1在Frame0上创建了一个WritePageGuard,接着线程2也尝试创建WritePageGuard,这时如果没有先释放BPM大锁再获取Frame的读写锁,线程2就会在持有BPM大锁的情况下阻塞在获取Frame的读写锁的步骤。此时如果线程1没有释放Frame0的WritePageGuard,接着继续尝试获取Frame1的WritePageGuard,就会在获取BPM大锁的步骤上阻塞。
-
获取完读写锁后,重新获取BPM大锁。
这步主要是为了外部调用构造函数的函数不会在BPM大锁上进行double free。
-
将该PageGuard设置为有效,返回。
这一套流程中最为重要的就是第2步,在持有BPM大锁的情况下将Frame设置为non-evictable,保证了接下来释放了BPM大锁同时还未获取Frame的读写锁的这个间隙,该Frame不会因为被驱逐而失去意义。
别忘了如果是WritePageGuard的话,直接把Frame.is_dirty设置为True
析构
析构也是很麻烦的一点,因为要避免double free。
我的做法是创建一个专门用于控制析构并发的锁,在进入Drop函数时获取该锁,然后进行各种处理之后将该PageGuard设置为非法,再释放该锁。
这样就让整个Drop过程原子化了,就算有多个线程同时调用了Drop,最后成功进行资源清理的也只会有一个,因为非法的PageGuard会直接跳过资源清理。
移动语义
在实现过程中还有一个让我头疼最久的就是移动语义。
虽然我个人自认为很熟悉C++,不过我上次写C++的项目都已经一年之前了,忘记了要怎么设计operator=(&&)和移动构造函数了。
其实很简单,先调用this->Drop()进行自身资源的清除,然后将that.is_valid设置为false就行。
对于operator=(&&),还要进行一次自赋值判断
if (this == &that) {
return *this;
}
如果赋值对象是自己就没有必要释放资源了,不然会造成不正确的结果。
Buffer Pool Manager
这个业务代码倒是没有啥好记的部分了。
主要就是那几个数据结构倒来倒去,无非就是在需要空闲空间的时候调用replacer,然后如果标记为脏就写回。
最头疼的还是一堆optional飘来飘去,事实证明这套所有值默认为引用的做法是很好的实践,现代C++也吸取了这个做法,不过这个接口的优雅程度嘛,感觉挺一般的。